For the final project of this class, I chose to deepen the analysis of the dataset I have previously studied for the Data Project: it is a collection of around 4,000 tweets, produced during Summer 2015 for #LabExpo, an experiment on Twitter proposed by the Italian start-up TwLetteratura connected to Expo Milano 2015. This experiment is based -as I previously mentioned in the blog post about my Data Project – on the methodology developed by TwLetteratura which takes advantage of Twitter’s peculiarities (synthesis, sharing, real-time interaction) to involve readers in a text: TwLetteratura establishes a schedule and defines a hashtag; everyone is invited to tweet by commenting, interpreting, or analyzing the text; the only rule to be respected is to follow the schedule and to insert the hashtag. Employing Twitter produces a ‘participate reception’ of a text: a new kind of reception which, differently from the traditional one, implies an explicit action by the readers.
¶ 2 Leave a comment on paragraph 2 0 #LabExpo started on July 13 and ended October 11, 2015: the text to comment was the Science Agreement, a scientific document written by scholars from more universities and research institutes all over the world in collaboration with Fondazione Giangiacomo Feltrinelli, which established the scientific program of Expo 2015. TwLetteratura defined six thematic shots to debate on, related to six passages of the document, each dedicated to a specific issue. Each of them has to be tweeted with the hashtag #LabExpo, followed a key word: #LabExpo/foodsec for Food security; #LabExpo/commons for Collective goods; #LabExpo/energy for Access to energy; #LabExpo/innovation for Tech and social innovation; #LabExpo/foodscape for Food and identity; #LabExpo/foodprod for Sustainable processes for food production. The passages were published both in Italian and in English on the websites of TwLetteratura and Fondazione Feltrinelli.
¶ 3 Leave a comment on paragraph 3 0 I have analyzed these tweets by using Voyant, to understand – through a textual analysis based on quantitative approach – how people absorb and re-interpret the text.
¶ 4
Leave a comment on paragraph 4 0
Theoretical basis
Before to analyze the results of the TwLetteratura’s experiment, I have briefly sketched the theoretical approaches which helped me to contextualize my study. On one hand, it is indeed related to the reception theory of the text, developed from the 1960s starting from the works of Jauss and Iser, which considers the reader as the most important function to define the meaning of a text. The second theoretical approach which I considered fundamental for my work is the broader field of the Digital Humanities, especially the study of the influence of the new digital approach to the production and the fruition of literary objects. These second field, even if not directly related with the text, provides me with the most relevant theoretical frame for my research, because it analyzes how the spread of the digital technologies is deeply influencing the way we read and write not only on the social networks but also on books and literature. As many scholars have already demonstrated, the digital is transforming not only the support where we read the books but, above all, it is reframing the roles of authors and readers. Allowing the readers – as the Web 2.0 has done – the possibility to co-operate in the construction of the text, this process is lowering the barriers between the two traditional roles of readers and authors, receiver and producer. This is exactly what the TwLetteratura’s projects have done, and for this reason I considered #LabExpo an interesting case study.
¶ 5
Leave a comment on paragraph 5 0
The analysis of the tweets
I collected the tweets produced for #LabExpo using Blogmeter, a social media collector platform which monitored #LabExpo by counting all the tweets containing the hashtag. The participants produced a total amount of 4,435 messages, counting both tweets and retweets (1,500 tweets), written by 130 users (the total amount of whom, counting also who retweeted at least one tweet, is 795). All the tweets were stored in Blogmeter, listed following these parameters: link to the original tweet; content of the tweet; author; date.
To analyze their content for my project, I employed Voyant, a “web-based text reading and analysis environment [,] a scholarly project that is designed to facilitate reading and interpretive practices for digital humanities students and scholars as well as for the general public”.
¶ 6
Leave a comment on paragraph 6 0
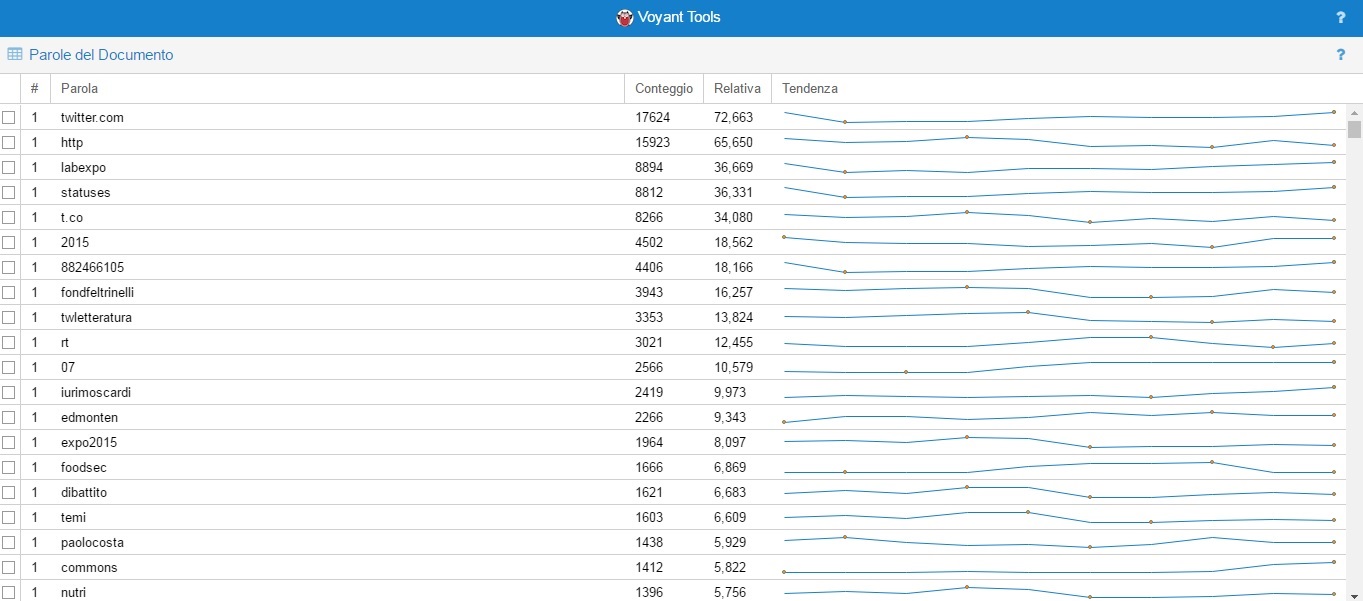
¶ 7 Leave a comment on paragraph 7 0
¶ 8 Leave a comment on paragraph 8 0 This first tool was very useful to measure the frequency of the words’ appearance, together with the weight of its relative frequency and also showing a chart which shows the trend of this frequency during all the project.
¶ 9 Leave a comment on paragraph 9 0 And, to better understand the real trend of the project, I relied on another of the Voyant tool: the Type Frequency Chart which “shows a line graph depicting the distribution of a word’s occurrence across a corpus”. This allowed me to create a graphic chart which shows the trend of all the six hashtags used for the projects. On the vertical line of the chart we have a scale of “raw frequencies: the absolute count for each document or document segment” (the actual relevance of every hashtag); on the horizontal line of the chart, instead, there are the segments of the documents, which I set up to 100 to have a more accurate representation of the trend (the standard number automatically set up by Voyant is 10). Because the tweets are listed in the document following a chronological order, from the older to the newest, this segment division follows also the time schedule of the project. All the hashtags have a different colors, so it is easy to understand the difference between them.
¶ 10 Leave a comment on paragraph 10 0
¶ 11
Leave a comment on paragraph 11 0
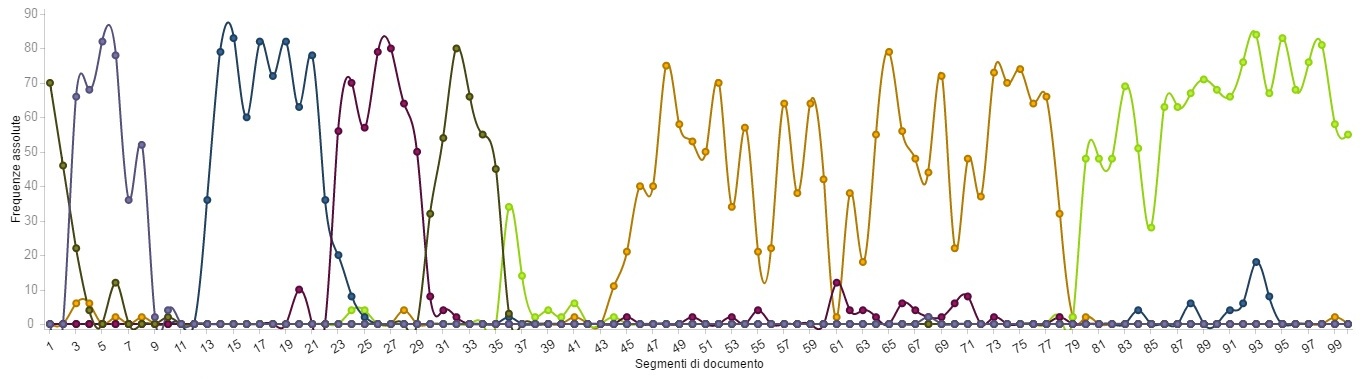
¶ 12
Leave a comment on paragraph 12 0
With another kind of analysis – through the Document Frequencies Grid – I focused on the six different hashtags: the number of their occurrences could be considered as a proof of the topic which the participants considered most valuable to be tweeted, so more interesting or fascinating. Counting the number of occurrences, we can establish this total:
– foodsec (#LabExpo/foodsec: food security): 1,686;
– commons (#LabExpo/commons: collective goods): 1,414;
– energy (#LabExpo/energy: energy): 749;
– innovation (#LabExpo/innovation: tech and social innovation): 544;
– foodscape (#LabExpo/foodscape: relationship of food and identity): 491;
– foodprod (#LabExpo/foodprod: sustainable processes for food production): 390.
These numbers allowed me to understand the general, negative trend of the project. From the third week the participation drastically decreased: the number of the tweets associated with the third hashtag are indeed around the half of the ones written the previous week. And this negative trend continues until the last week, when the tweets are one fourth of the tweets associated with the first hashtag: 75% less tweets in seven weeks.
¶ 13 Leave a comment on paragraph 13 0 Finally, I employed the Document Type Collocate Frequencies Grid, which “provides an ordered list of word collocation for a specified word and document” by listing all the words with which a key term is more commonly associated. I employed, for this analysis, all the six different hashtags, obtaining for all of them a list composed of 200 words. And, to define hypothetical trends followed by participants during their discussions, I chose to list the first and the last 10 words of every list. I obtained, in this way, 6 different charts, useful to define the hypothetic areas which the participants could have associated with the hashtags: if it is not possible to establish the reason behind these associations, at least we could try to understand what the participants associated with the different topics.
¶ 14 Leave a comment on paragraph 14 0 For instance, the 10 words more frequently associated with #LabExpo/foodsec are:
¶ 15
Leave a comment on paragraph 15 0
– Alimentare (dietary): 654;
– Cibo (food): 565;
– Sicurezza (security): 465;
– Disponibilità (availability): 307;
– Risorse (resources): 277;
– Accesso (access): 217;
– Food (in English): 215;
– Stabilità (stability): 200;
– Spreco (wasting): 199;
– Utilizzo (employment): 186.
¶ 16 Leave a comment on paragraph 16 0 While the 10 least associated with it are:
¶ 17
Leave a comment on paragraph 17 0
– Davvero (really): 34;
– Animali (animals): 34;
– Vincitori (winners): 33;
– Possibilità (possibility): 33;
– Maschi (males): 33;
– Giusitiza (justice): 33;
– Economica (economic): 33;
– Doppia (double): 33;
– Diventare (to become): 33;
– Asia 33.
This allowed me to speculate about the associations of words and hashtag. For instance, here the food security topic seems to have arisen question about the availability of food and resources, the access to the food, its production and its wasting: in other words, how the food is produced and its availability. It is indeed relevant that ‘Justice’ is between the words less associated with the hashtag, as ‘agroecology’ (a possible solution for the problem of the food security), ‘valore’ (value) and ‘animali’ (animals).
¶ 18
Leave a comment on paragraph 18 0
Conclusion
I conducted this analysis trying to identify the trends followed by the participants: to do so, I applied digital tools for the text analysis of their tweets. I have worked in this way because #LabExpo employed a methodology which expresses an ‘active reception’ of the text. I consider the tweets as a good example of how people has received the text. In this way, a community of people reads together – experimenting with social reading – and the participants become authors – experimenting the possibility of interaction as a way to create a new content. Moreover, participating to #LabExpo has allowed users to directly manipulate the content of the text: Twitter is a social space where each user has the same authority as the others, allowing the social interaction between participants. Consequently, their tweets create a new space where comment and reshaping of the book have the same value, reducing the difference between author, reader and critic.
For all these reasons, I considered #LabExpo a case study for the discussion of a new, more active and participated reception of the text, which is directly expressed by the tweets written by the participants to the project. More fundamentally, this new active participation is a skill allowed only by Twitter.
2 Comments
Hi Iuri, nice work! The idea of using Twitter as a participatory reading platform is fascinating. Personally, I find that platforms offering collaborative annotations like the one used for Debates in the DH (http://dhdebates.gc.cuny.edu/) or Medium (https://medium.com) help me get to the point more easily. TwLetteratura seems to be somewhere in the middle ground of such platforms and live conference tweets.
I wonder if the participatory mode of reading also impacts the content of the created text. For example, do the word frequencies in the tweets differ from the word frequencies in the original text? If so, I also wonder how it would be different from a single person’s review—although single person review may not exist, and this is perhaps way out of your project’s scope.
Also, it was interesting to see the participation rate dropping; something to bear in mind when conducting a digital project.
Hi Achim,
thank you very much for your comment and sorry for my late reply.
My intention was to discover the relation between the original text and the tweets: by analizing the tweets content, I would like to define the trends followed by users to participate to a project like this. Your suggestion about word frequencies between the original text and the tweets sounds fascinating: maybe I will develop it for a paper in the future.
I agree about the participation rate data: it is very interesting, and it could be much more interesting to understand if this dropping was due to the kind of text chosen or not.
Thank you very much again, and I hope to see you again during next semester.