¶ 1 Leave a comment on paragraph 1 0 The data set I chose for my project is a collection of tweets, produced during Summer 2015 for #LabExpo, an experiment on Twitter proposed by the Italian start-up TwLetteratura connected to Expo Milano 2015. This experiment is based on the methodology developed by TwLetteratura, which takes advantage of Twitter’s peculiarities (synthesis, sharing, real-time interaction) to involve readers in a text: TwLetteratura establishes a schedule and defines a hashtag; everyone is invited to tweet, commenting, interpreting, or analyzing the text; the only rule to be respected is to follow the schedule and to insert the hashtag. Employing Twitter produces a ‘participate reception’ of a text: a new kind of reception which, differently from the traditional one, implies an explicit action by the readers. I have analyzed these tweets by using Mallet, to understand how people absorb and re-interpret the text.
¶ 2
Leave a comment on paragraph 2 0
#LabExpo
#LabExpo started on July 13 and ended October 11, 2015: the text to comment was the Science Agreement, a scientific document written by scholars from more universities and research institutes all over the world in collaboration with Fondazione Giangiacomo Feltrinelli, which established the scientific program of Expo 2015. TwLetteratura defined six thematic shots to debate on, related to six passages of the document, each dedicated to a specific issue. Each of them has to be tweeted with the hashtag #LabExpo, followed a key word: #LabExpo/foodsec for Food security; #LabExpo/commons for Collective goods; #LabExpo/energy for Access to energy; #LabExpo/innovation for Tech and social innovation; #LabExpo/foodscape for Food and identity; #LabExpo/foodprod for Sustainable processes for food production. The passages were published both in Italian and in English on the websites of TwLetteratura and Fondazione Feltrinelli.
¶ 3
Leave a comment on paragraph 3 0
The tweets
I collected the tweets produced for #LabExpo using Blogmeter, a social media collector platform which monitored #LabExpo by counting all the tweets containing the hashtag. The participants produced a total amount of 4,435 messages, counting both tweets and retweets (1,500 tweets), written by 130 users (the total amount of whom, counting also who retweeted at least one tweet, is 795). The tweets could be analysis, interpretation, comments to the text, and contain other kind of data different from written text (pictures, videos, links). All the tweets were stored in Blogmeter, and I downloaded in a .xls file format; they were listed following these parameters: link to the original tweet; content of the tweet; author; date.
To analyze their content for my project, I employed Mallet, a “Java-based package for statistical natural language processing, document classification, clustering, topic modeling, information extraction, and other machine learning applications to text”: I want to thank you JoJo for having provided my a very useful tutorial, because I am not an expert of data analysis and I have never used Mallet before.
¶ 4 Leave a comment on paragraph 4 0 First of all, I created a .txt file from my .xls file containing all the tweets: Mallet could analyze only .txt. After that, I asked Mallet to analyze the file limiting the number of topics to 20, enough to have a clear situation of the trend. Moreover, I included also the command –optimize-interval, so the final file contained also an “indication of the weight of that topic” (as the tutorial states). The result was a .txt file, which I exported into a .xls file, obtaining this:
¶ 5
Leave a comment on paragraph 5 0
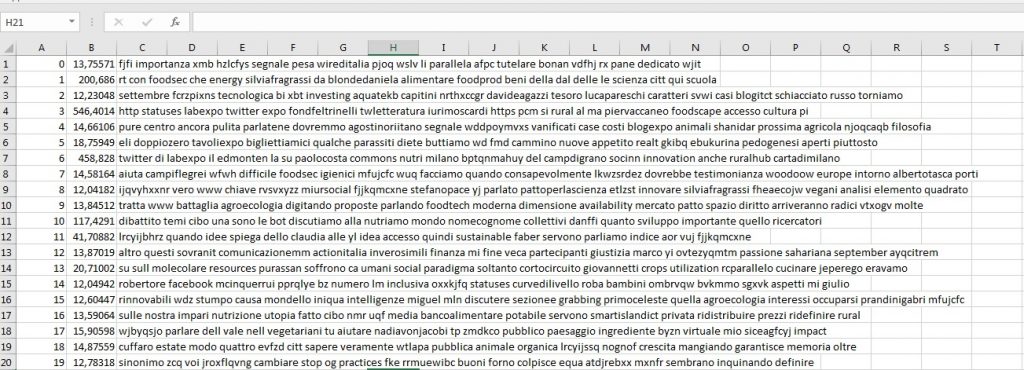
¶ 6
Leave a comment on paragraph 6 0
On the first column (A), numbers 0 to 19 identify the topics; on the second column (B), the weight of each topic; the remaining part, the content of the topic.
Unfortunately, Mallet apparently does not recognize Italian language, and the majority of the tweets were written in Italian; so, the topics contain also words without a semantic meaning, such as article or preposition. Mallet has instead a specific command to exclude this kind of information from texts written in English.
¶ 7
Leave a comment on paragraph 7 0
I will consider now the 4 most relevant topics, and the data they contain.
– Topic 3: “twitter”, “labexpo”, “foodscape”, the hashtag employed to comment the section of the text related to Food and identity, “accesso” (access), and “cultura” (culture).
– Topic 6: “commons”, “nutri” (feed, related to Expo payout “Feed the planet”), and “innovation”.
– Topic 1: “foodsec” (hashtag for the section about Food security), “energy”, “alimentare” (food), “foodprod” (the hashtag for Sustainable processes for food production), and “scienza” (science).
– Topic 10: “dibattito” (debate), “temi” (argument), “cibo” (food), “discutiamo” (discuss), “nutriamo” (feed), “mondo” (world), “collettivi” (commons), “sviluppo” (development), and “ricercatori” (researcher).
¶ 8 Leave a comment on paragraph 8 0 Even if these data could have only a statistical meaning, based on their frequency we could have a more precise understanding of some trends of the project. For instance, the relevance of “foodscape”, “foodsec”, “foodprod” suggest that these sections of the text were the most tweeted: here, readers felt more involved or they were most interested in. It is also relevant to find words in English, such as “innovation” or”commons”: this witnesses the international character of the project. Finally, the presence of words from the same semantic/thematic area seems to prove that participants understood the purposes of the project: to make people aware of the sustainability of the production of what is necessary for men today. This is relevant especially with words related to food.
¶ 9 Leave a comment on paragraph 9 0 This analysis allowed me to understand some trends which could be applied to understand how users participate to the project; this is also a first approach, and I would like to deepen it taking advantage of Mallet’s opportunity.
4 Comments
Great job explaining how, when, and where you collected your data. You may want to consider whether or not any of the images contained in the tweets are images of text longer than the character limit for Twitter. Also, are the Tweets from the dates of the event only? How many people use the hashtag before/after the event? We can begin to ask around about topic modeling applications that can handle Italian. In the meantime, you may also want to consider TXM, which is a European-funded text analysis tool… I think I remember them saying that that Italian was one of the languages they supported. Looking forward to next steps….
Dear professor, thank you very much for the suggestion.
Luri, really interesting project to use tweets and the dataset you’ve focused in on seems promising, especially given the broad political and policy themes. Nice, decent dataset size (1,500 tweets from 795 discrete individuals). Any sense demographically of who these people are in class, geographic, age, and ethnic terms? I’m glad there’s a European version of Mallet, per Lisa’s note, that works with Italian (my fingers are crossed, as we say in English)! Looking forward to the next step. One other thought: do you mean “participant reaction” rather than “participate reaction”? The former uses the noun; the latter the verb.
Dear professor Brier,
sorry for this very late reply.
Thank you for your suggestions.